About Me
I am a 4th year Ph.D. student in the Data Analytics Lab in ETH Zürich, supervised by Thomas Hofmann. I am interested in understanding how models learn from data and how we can make them more efficient and robust. During my Ph.D., I have completed internships at Google DeepMind and Meta GenAI. Prior to my Ph.D., I completed my M.Sc. in Data Science at ETH Zürich and a Diploma in Computer Engineering from the National Technical University of Athens.
News
I will be joining Anthropic to work on multi-modal pretraining!
Our paper on speculative decoding got an Oral in ICLR, see you in Singapore!
Our paper on sycophancy is accepted at COLM, see you in Philadelphia!
I will be joining Meta GenAI until mid November. Going to be working on topics around VLM (inference) efficiency!
I will be presenting in ICML our papers on navigating scaling laws (Spotlight) and concept guidance in LLMs.
I will be presenting in ICLR our papers on fusing transformer models and meta-pruning (Spotlight).
I will be presenting in NeurIPS our papers on dynamic context pruning (Spotlight), OpenAssistant conversations (Oral) and scaling MLPs!
I will be joining Google DeepMind until the end of the year, working on personalized evaluation and finetuning of VLMs.
I will be presentig our paper on using RL for dynamic graph predictions in ICCV.
Our paper using CLIP for 3D Scenes, got an Oral in BMVC!
Our paper on distillation will be presented in ICML.
Featured Publications
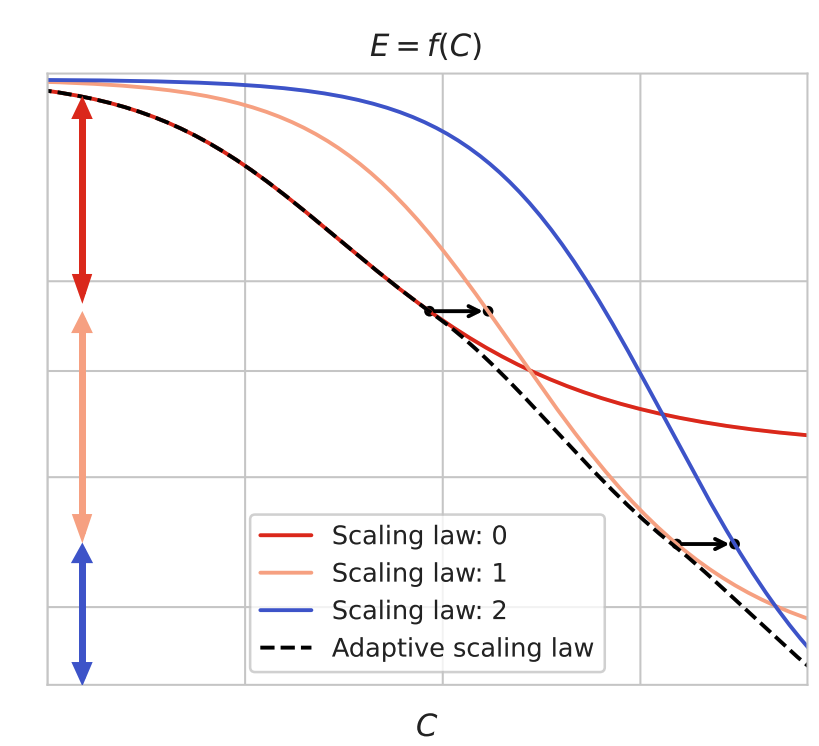
Navigating Scaling Laws: Compute Optimality in Adaptive Model Training paper
We explore adaptive training methods for deep learning models, challenging the traditional static model paradigm that follows fixed neural scaling laws. By allowing models to change their "shape" during training, we propose to optimally traverses scaling laws, reducing computational resource requirements for training. We do this for a variety of "shapes" and models across different modalities.
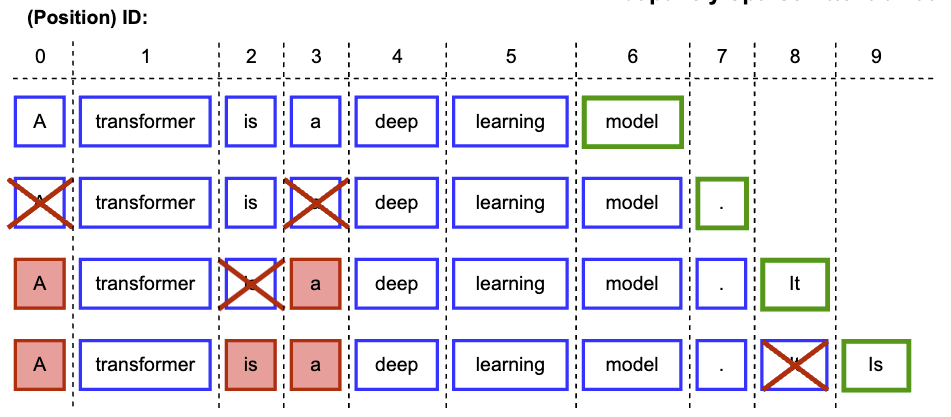
Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers paper
We introduce a dynamic context pruning method for autoregressive Transformers to improve efficiency and interpretability when processing long sequences. We learn to prune uninformative tokens dynamically during inference, reducing memory and computational costs while maintaining model expressiveness. The pruning mechanism, which is controlled by a sparsity parameter, can be easily integrated into pre-trained models via fine-tuning.
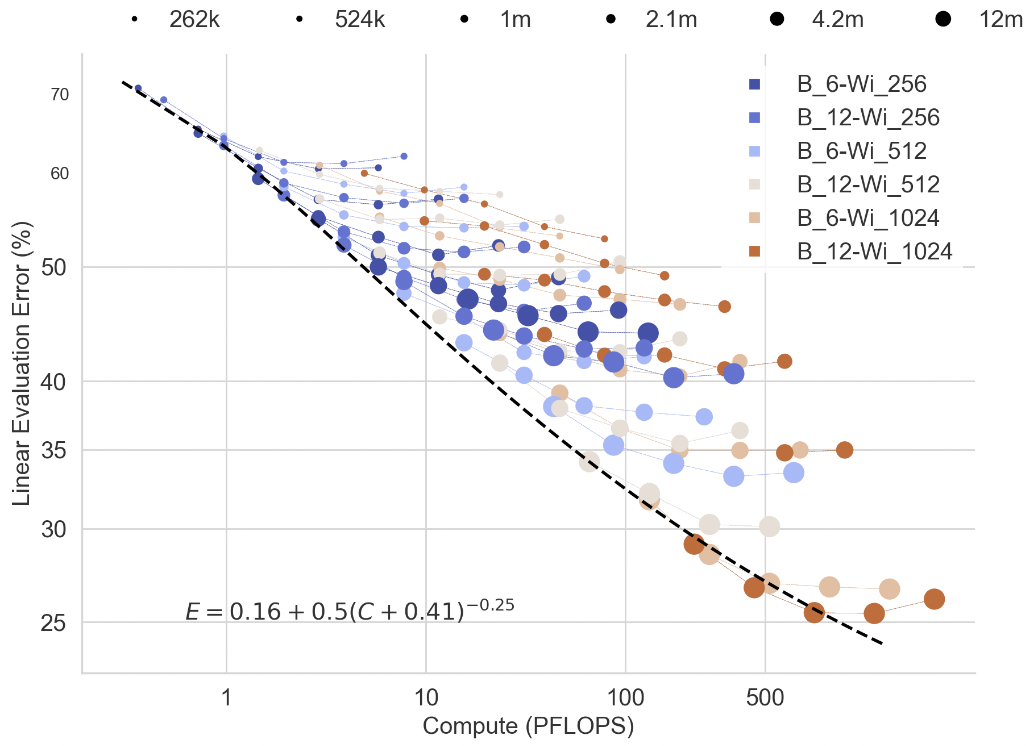
Scaling MLPs: A Tale of Inductive Bias paper
We investigates the limits of multi-layer perceptrons, addressing the gap between their theoretical prominence and practical underuse in deep learning. We demonstrate that MLPs, despite lacking vision-specific inductive biases, achieve strong performance when scaled effectively, highlighting that inductive bias can be compensated with sufficient compute and data.
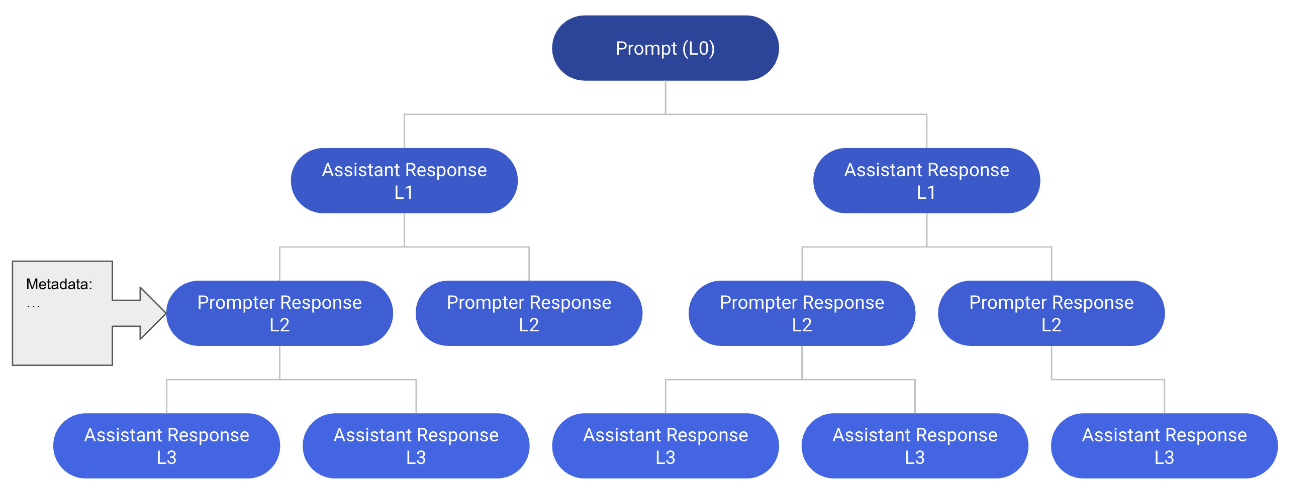
OpenAssistant Conversations - Democratizing Large Language Model Alignment paper
We address the challenge of aligning large language models (LLMs) with human preferences to enhance usability and accessibility. While alignment techniques like supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) improve model performance, they rely on expensive, proprietary high-quality human feedback data. To democratize alignment research, we introduce the OpenAssistant Conversations dataset, and train large models to evaluate its effectiveness.
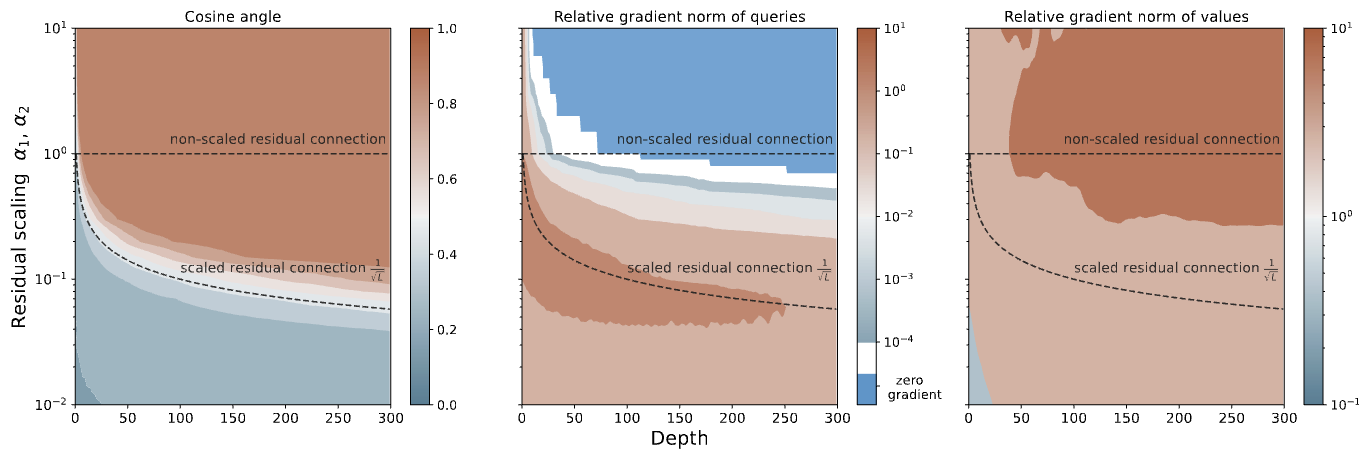
Signal Propagation in Transformers: Theoretical Perspectives and the Role of Rank Collapse paper
We investigate the phenomenon of rank collapse in Transformers, where token representations become highly aligned or degenerate at initialization, leading to vanishing gradients. We identify this issue as a significant barrier to training, particularly in deeper networks. By analyzing the underlying causes, we propose a depth-dependent scaling of residual branches to mitigate rank collapse and stabilize token representations.
Contact
You can reach me at:


